Original Link: https://www.anandtech.com/show/5094/nvidias-maximus-technology-quadro-tesla-launching-today
NVIDIA’s Maximus Technology: Quadro + Tesla, Launching Today
by Ryan Smith on November 14, 2011 9:00 AM ESTNVIDIA’s Maximus Technology – Quadro + Tesla, Launching Today
Back at SIGGRAPH 2011 NVIDIA announced Project Maximus, an interesting technology initiative to allow customers to combine Tesla and Quadro products together in a single workstation and to use their respective strengths. At the time NVIDIA didn’t have a launch date to announce, but as this is a software technology rather than a hardware product, the assumption has always been that it would be a quick turnaround. And a quick turnaround it has been: just over 3 months later NVIDIA is officially launching Project Maximus as NVIDIA Maximus Technology.

So what is Maximus Technology? As NVIDIA likes to reiterate to their customers it’s not a new product, it’s a new technology – a new way to use NVIDIA’s existing Quadro and Tesla products together. There’s no new hardware involved, just new features in NVIDIAs drivers and new hooks exposed to application developers. Or put more succinctly, in the same vein that Optimus was a driver technology to allow the transparent combination of NVIDIA mobile GPUs with Intel IGPs, Maximus is a driver technology to allow the transparent combination of NVIDIA’s Quadro and Tesla products.
With Maximus NVIDIA is seeking to do a few different things, all of which come back to a single concept: utilizing Quadro and Tesla cards together at the tasks they’re best suited at. This means using Quadro cards for graphical tasks while using Tesla for compute tasks where direct graphical rendering isn’t necessary. Ultimately this seems like an odd concept at first – high end Quadros are fully compute capable too – but it’s something that makes more sense once we look at the current technical limitations of NVIDIA’s hardware, and what use cases they’re proposing.
Combining Quadro & Tesla: The Technical Details
The fundamental base of Maximus is NVIDIA’s drivers. For Maximus NVIDIA needed to bring Quadro and Tesla together under a single driver, as they previously used separate drivers. NVIDIA has used a shared code base for many years now, so Tesla and Quadro (and GeForce) were both forks of the same drivers, but those forks needed to be brought together. This is harder than it sounds as while Quadro drivers are rather straightforward – graphical rendering without all the performance shortcuts and with support for more esoteric features like external synchronization sources – Tesla has a number of unique optimizations, primarily the Tesla Compute Cluster driver, which moved Tesla out from under Windows’ control as a graphical device.
The issue with the forks had to be resolved, and the result was that NVIDIA was finally able to merge the codebase back into a single Quadro/Tesla driver as of July with the 275.xx driver series.
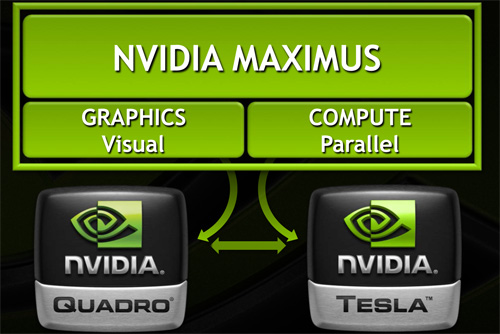
But this isn’t just about combining driver codebases. Making Tesla and Quadro work in a single workstation resolves the hardware issues but it leaves the software side untouched. For some time now CUDA developers have been able to select what device to send a compute task to in a system with multiple CUDA devices, but this is by definition an extra development step. Developers had to work in support for multiple CUDA devices, and in most cases needed to expose controls to the user so that users could make the final allocations. This works well enough in the hands of knowledgeable users, but NVIDIA’s CUDA strategy has always been about pushing CUDA farther and deeper in the world in order to make it more ubiquitous, and this means it always needs to become easier to use.
This brings us back to Optimus. With Optimus NVIDIA’s goal was to replace manual GPU muxing with a fully transparent system so that users never needed to take any extra steps to use a mobile GeForce GPU alongside Intel’s IGPs, or for that matter concern themselves with what GPU was being used. Optimus would – and did – take care of it all by sending lightweight workloads to the IGP while games and certain other significant workloads were sent to the NVIDIA GPU.
Maximus embodies a concept very similar to this, except with Maximus it’s about transparently allocating compute workloads to the appropriate GPU. With a unified driver base for Tesla and Quadro, NVIDIA’s drivers can present both devices to an application as usable CUDA devices. Maximus takes this to its logical conclusion by taking the initiative to direct compute workloads to the Tesla device; CUDA device allocation becomes a transparent operation to users and developers alike, just like GPU muxing under Optimus. Workloads can of course still be manually controlled, but at the end of the day NVIDIA wants developers to sit back and do nothing, and leave device allocation up to NVIDIA.
As with Optimus, NVIDIA’s desires here are rather straightforward: the harder something is to use, the slower the adoption. Optimus made it easier to get NVIDIA GPUs in laptops, and Maximus will make it easier to get CUDA adopted by more programs. Requiring developers to do any extra work to use CUDA is just one more thing that can go wrong and keep CUDA from being implemented, which in turn removes a reason for hardware buyers to purchase a high-end NVIDIA product.
Why Combine Quadro & Tesla?
So far we’ve covered how NVIDIA will be combining Quadro, but the more interesting question is “why?” In the NVIDIA hierarchy, Quadro is NVIDIA’s leading product. On the graphics side it’s fully unlocked, supporting quad-buffers, uncapped geometry performance, and uncapped viewport performance, while on the compute side it offers full speed FP64 support. Furthermore it’s available in the same configurations as a Tesla card, featuring the same number of CUDA cores and memory. Short of TCC, if you can compute it on a Tesla, you can compute it on a Quadro.
This actually creates some complexities for both NVIDIA and users. On a technical level, Fermi’s context switching is relatively fast for a GPU, but on an absolute level it’s still slow. CPUs can context switch in a fraction of the time, giving the impression of a concurrent thread execution even when we know that’s not the case. Furthermore for some reason context switching between rendering and compute on Fermi is particularly expensive, which means the number of context switches needs to be minimized in order to keep from wasting too much time just on context switching.
As a result of the time needed to context switch, Quadro products are not well suited to doing rendering and compute at the same time. They certainly can, but depending on what applications are being used and what they’re trying to do the result can be that compute eats up a great deal of GPU time, leaving the GUI to only update at a few frames per second with significant lag. On the consumer side NVIDIA’s ray-tracing Design Garage tech demo is a great example of this problem, and we took a quick video on a GTX 580 showcasing how running the CUDA based ray-tracer severely impacts GUI performance.
Alternatively, a highly responsive GUI means that the compute tasks aren’t getting a lot of time, and are only executing at a fraction of the performance that the hardware is capable of. As part of their product literature NVIDIA put together a few performance charts, and while they should be taken with a grain of salt, they do quantify the performance advantage of moving compute over to a dedicated GPU.
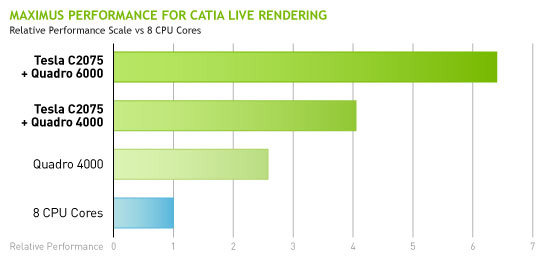
For these reasons if an application needs to do both compute and rendering at the same time then it’s best served by sending the compute task to a dedicated GPU. This is the allocation work developers previously had to take into account and that NVIDIA wants to eliminate. At the end of the day the purpose of Maximus is to efficiently allow applications to do both rendering and compute by throwing their compute workload on another GPU, because no one wants to spend $3500 on a Quadro 6000 only for it to get bogged down.
It’s worth noting that this situation closely mirrors the situation for software developers. For debug purposes NVIDIA recommends programmers have two GPUs, so that one GPU can be locked down debugging a compute or rendering task as necessary, while the other GPU is available to display the results. So NVIDIA encouraging users to have two GPUs for technical reasons is not new, but it is expanded. It also means there’s an obvious avenue for further development as NVIDIA wants to move GPU multitasking closer and closer to where CPU multitasking is today.
Moving on, the second reason NVIDIA is pursing Maximus is a result of their own actions. Because Quadro is NVIDIA’s leading product, it commands a leading price: a Quadro 6000 card is $3500 or more. This is a product of NVIDIA’s well engineered market segmentation – a GF110 GPU can be in a $500 GTX 580, a $2500 Tesla C2075, or a $3500 Quadro 6000. By disabling a few critical features on other products (e.g. geometry performance or FP64 performance) NVIDIA can push customers into buying a product at a price NVIDIA believes is best for the target market.
So what’s the problem? The Quadro 6000 is both a highly capable rendering product at a highly capable compute product, but not every professional user needs that much rendering power even if they need the compute power. Those users still need a Quadro card for its uncapped rendering performance, but they don’t necessarily need features such as Quadro 6000’s massive geometry throughput. The result is that NVIDIA was pricing themselves right out of their own market.
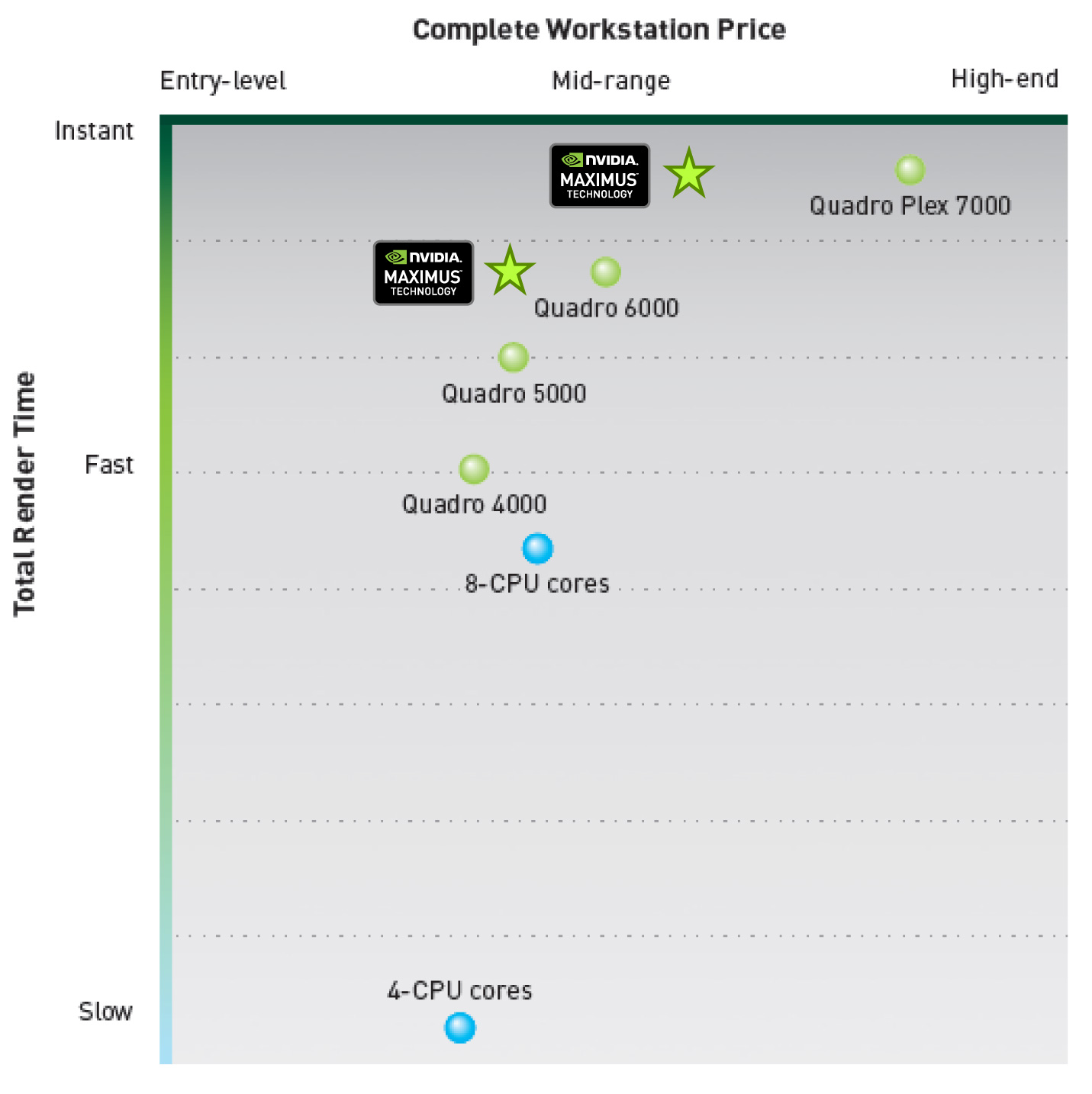
The solution to that is combining Quadro and Tesla. Maximus allows a Tesla C2075 to be used with any Fermi based Quadro (600/2K/4K/5K/6K), which allows NVIDIA to more appropriately tap the overlapping market of Quadro users that need top-tier compute performance. The end result for those users is that they not only pay less – a Quadro 2000 and a Tesla C2075 is $3000 versus over $3500 for a single Quadro 6000 – but they gain the aforementioned advantages of not having conflicting tasks slowing down the performance of a single Quadro card. Admittedly this is a lot of effort on NVIDIA’s part to tap a very specific market, but at the end of the day the professional market is a highly profitable market, making it worth NVIDIA’s time.
Final Words
Wrapping things up, NVIDIA has made it clear that they’re going to be pushing Maximus hard right out of the gate. Today of course was also the launch of Intel’s new Sandy Bridge E platform for high-end desktops and workstations, and in this industry there’s very little coincidence. It’s in NVIDIA’s interest to latch into workstation upgrade sales, and this is how you do it. They’ve already lined up HP, Lenovo, Fujitsu, and Dell to offer workstations pre-configured for Maximus, and we’re told those workstations will be made available for purchase today.
As to whether Maximus will be successful or not, this is going to depend both on software and marketing. On the software side NVIDIA needs to deliver on the transparency Maximus promises to developers and users – the concept is simple, but for the professional market the execution must be precise. Optimus graphics switching misbehaves now and then, but professional users will not be as willing to put up with any undesired behavior out of Maximus.
Marketing on the other hand is equally about promoting Maximus and promoting CUDA. A lot of NVIDIA’s promotional material for Maximus could easily be confused for CUDA promotional material, and this is because the videos and case studies are largely about how CUDA improved a process or a product while Maximus was the icing on the cake. Though we consider CUDA old, the fact of the matter is that much of the professional market NVIDIA is targeting has still not heard of CUDA, or has a limited understanding at best. As such NVIDIA will be using the launch of Maximus to promote the benefits of CUDA to certain targeted markets such as manufacturing, design, and broadcasting, just as much as they will be promoting the benefits of having multiple GPUs.
Normally we don't publish a copy of NVIDIA's press materials with any articles, but in this case I'm making an exception. NVIDIA put together a number of use cases for Maximus that do a great job of pointing out the market they're going after with Maximus and their latest marketing push.
After 25 years of design and creative professionals anticipating a workstation that simultaneously performs complex analysis and visualization, NVIDIA announced today its arrival, with the introduction of NVIDIA® Maximus™ technology.
The new offering unleashes productivity and creativity, dramatically accelerating work by enabling a single system for the first time to simultaneously handle interactive graphics and the compute-intensive number crunching associated with the simulation or rendering of the results. These previously needed to be done in separate steps or on separate systems.
NVIDIA Maximus achieves this by bringing together the professional 3D graphics capability of NVIDIA Quadro® professional graphics processing units (GPUs) with the massive parallel-computing power of the NVIDIA Tesla™ C2075 companion processor -- under a unified technology that transparently assigns work to the right processor and is certified by industry leading application vendors.
"To those of us who have spent their careers focused on workstations, NVIDIA Maximus represents a revolution," said Jeff Brown, general manager, Professional Solutions Group, NVIDIA. "Previous workstation architectures forced designers and engineers to do compute-intensive work and graphics-intensive work serially and often offline. They can now do them at the same time, on the same machine, allowing professionals to explore more ideas faster and converge quickly on the best possible answers."
With NVIDIA Maximus-enabled applications -- such as those from Adobe, ANSYS, Autodesk, Bunkspeed, Dassault Systèmes and MathWorks -- GPU compute work is assigned to run on the NVIDIA Tesla companion processor. This frees up the NVIDIA Quadro GPU to handle graphics functions, ensuring the quality and performance demanded by professional users.
"The real advantage of the Maximus technology is flexibility and increased productivity," said Tim Ong, vice president of Mechanical Engineering for Sunnyvale, CA-based Liquid Robotics. "Allowing each engineer to do multiple things at once is transformative for our workflow. It's a tremendous tool to allow my engineers to be flexible, to multitask, and to be more productive because they're not waiting on computational power."
NVIDIA Maximus Technology Immediately Available
The world's leading workstation OEMs -- including HP, Dell, Lenovo, and Fujitsu -- are all offering workstations featuring NVIDIA Maximus technology, available for configuration and purchase immediately.
NVIDIA Maximus desktop workstation configurations start with the pairing of the NVIDIA Quadro 600 ($199 MSRP, USD) + NVIDIA Tesla C2075 ($2,499 MSRP, USD).
Quotes
Product Design, Styling and Visualization
"Autodesk's 3ds Max 2012 has received top scores by reviewers, and one of the reasons they cite is the new iray photorealistic renderer from NVIDIA. We've taken this to another level with our announcement of the ActiveShade integration with iray -- giving our subscription users an interactive rendering experience -- especially if they are using an NVIDIA Quadro GPU, or the new NVIDIA Maximus solution that's up to 9X faster than a single CPU."
-Ken Pimentel, director, Media Design, Autodesk
"Bunkspeed PRO 2012 combines Bunkspeed Shot PRO and Bunkspeed Move PRO into one easy to use interactive ray tracing package built on CUDA powered NVIDIA iray. NVIDIA Maximus powered workstations allow designers, engineers, marketers and architects to render their 3D models with Bunkspeed PRO up to 8x faster than on CPUs alone, with a whole new level of realism and interactivity."
-Philip Lunn, founder and CEO, Bunkspeed
"By harnessing the power of GPU computing we have been able to create a more productive, high-performance, interactive user experience and, at the same time, dramatically increase the realism of visualization tools available for designers and engineers within CATIA V6. With NVIDIA Maximus, users will be able to experience the full power of these new visualization tools in their product design workflow."
-Xavier Melkonian, director, CATIA Shape Domain, Dassault Systèmes
Engineering Simulation
"GPU computing can dramatically accelerate ANSYS engineering software simulations on workstations, in some cases doubling the number of simulations that can be considered and helping customers to adopt more pervasive use of engineering simulation. With NVIDIA Maximus platforms widely available, enterprises can now more easily take advantage of ANSYS at their desk for both interactive and computationally intensive tasks."
-Barbara Hutchings, director of strategic partnerships at ANSYS
Digital Video Content Creation
"Adobe® Premiere® Pro CS5.5 and the Adobe Mercury Playback Engine accelerated by NVIDIA GPUs continue to lead the industry with exceptional performance in non-linear editing. NVIDIA Maximus enables video professionals to create complex, multiple-layer projects faster, further increasing their productivity and empowering their creativity."
-Bill Roberts, director of professional video and audio product management, Adobe
Technical Computing
"MATLAB users want to take advantage of GPUs to achieve significant speed-up of their applications quickly and easily, without making major changes to their MATLAB code. The wide availability of pre-qualified NVIDIA Maximus systems for MATLAB gives our users access to commodity platforms that deliver great productivity."
-Loren Dean, director of Engineering, MATLAB Products, MathWorks
Workstation OEMs
"HP's Z Workstations meet the needs of some of the most compute-intensive industries in the world. With NVIDIA Maximus technology, HP is providing a powerful, new performance solution that will enable our customers to design and analyze more efficiently, ultimately increasing ROI."
-Jeff Wood, vice president, Worldwide Marketing, Commercial Solutions, HP
HP entry-level Z400 and top-of-the line Z800 workstations are available now worldwide.
"NVIDIA Maximus enables our customers to accelerate their visualization and complex parallel workloads. When combined with Dell Precision workstation solutions, our design, research and digital content creation customers can increase their interactivity, productivity and creative freedom."
-Greg Weir, marketing director, Dell Precision Workstation Product and ISV Marketing
Dell Precision T5500, R5500, and T7500 are available now worldwide.1
"Application acceleration speeds up the design process and product delivery, and with NVIDIA Maximus on Lenovo ThinkStations, users have the parallel processing power they need to boost productivity, creativity, and time-to-market. NVIDIA Maximus-class ThinkStation S20, C20, and D20 workstations transform workflows with computing and visualization capabilities that empower engineers, designers and digital content creators to achieve amazing results exponentially faster."
-Rob Herman, director of Product and Vertical Solutions, ThinkStation Business Unit, Lenovo
Lenovo ThinkStation S20, C20 and D20 workstations are available now worldwide.
"Our advanced and superior line of Fujitsu CELSIUS workstations, including our CELSIUS M and R series, become even more powerful and versatile performers with NVIDIA Maximus technology. Our customers demand the most innovative technology for driving the new generation of high-performance 3D modeling, animation, real-time visualization, analysis, and simulation applications -- NVIDIA Maximus-powered CELSIUS workstations provide the customized visualization plus computation performance they need."
-Dieter Heiss, head of Workplace Systems at Fujitsu Technology Solutions
Fujitsu CELSIUS M470, R570 and R670 workstations are available now in EMEAI and Japan.
For more information about NVIDIA Maximus Technology, visit: www.nvidia.com/maximus.
Follow NVIDIA Workstation/Quadro on YouTube and Twitter: @NVIDIAQuadro.






