Original Link: https://www.anandtech.com/show/2795
Optimizing for Virtualization, Part 2
by Liz van Dijk on June 29, 2009 12:00 AM EST- Posted in
- IT Computing
Preface
We ended the first part of this article by talking about jumbo frames, having discussed some CPU considerations and general best practices for various situations.
In the meantime, the lab got the opportunity to sit down with VMware’s Scott Drummonds, who was able to provide us with some more interesting information on this subject, and a couple of our readers pointed out some of the problems they’ve been experiencing, along with the solutions. We are really happy with the overwhelmingly positive reactions we have received to Part 1, and hope Part 2 will continue to help out the people who need to work with ESX on a regular basis to get the most out of the product.
Before we dive into the more “structured” part of the article, we would like to mention a possible issue brought up by one of our readers, yknott. Apparently, IRQ sharing on certain platforms can cause a rather large performance hit in cases where the the interrupt line is used alternatively by ESX’s service console and the VMkernel. The service console is the actual console that can be logged into when an administrator wants to check out for example esxtop, and can as such take control of certain devices to perform its tasks. The problem seems to occur when both the VMkernel and the service console have control over the same device, which is something that can be checked for when displaying the /proc/vmware/interrupts file, as documented in this article of the VMware knowledge base.
Layout changes: noticing a drop in sequential read performance?
When considering virtualization of a storage system, an important step is researching how actual LUN layout changes when migrating to a virtualized environment. Adding an extra layer of abstraction and consolidating everything into vmdk-files can sometimes make it complicated to keep up with how it all maps to actual physical storage.
By consolidating previously separate storage systems into a single array, servicing multiple VM’s, we notice a change in access patterns. Because of queueing systems on all levels (guest, ESX and the array itself), what are actually supposed to be sequential reads coming from a single system get interleaved with the reads of other VM’s, resulting in a random access pattern. Keep this in mind when you notice a drop in otherwise solidly performing sequential read operations.
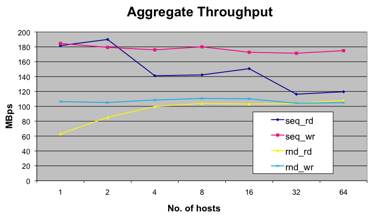
An important aspect about these queues is the fact that they can be tampered with. If, for example, one would like to perform a test on a single VM that really requires it to get the most out of the LUN as possible, ESX is able to change its queues to temporarily fit the requirements. As it is, the queues’ standard size is 32 outstanding IO’s per VM, which should be optimal for a standard VM-layout.
Linux database consideration
Specifically for Linux database machines, there is another important factor to consider (Windows takes care of this automatically). This is something we need to be extra careful about during the development of vApus Mark II: the Linux version of our benchmark suite, but anyone using databases under Linux should be familiar with this. It is generally recommended to cache as much of the database in the database cache, rather than allowing the more general OS buffer cache to take care of it. This recommendation once more plays a big role when virtualizing the workloads, as managing the file system buffer pages is more costly to the hypervisor.
This parameter should be set from inside the database system however, and usually comes down to configuring O_DIRECT mode as the preferred method of approaching storage (in mysql, it comes down to setting the innodb_flush_method to O_DIRECT).
Last but not least in our discussion, the use of proper software, and the configuration thereof. ESX offers a veritable waterfall of settings for those who are willing to dig in and tweak them, but they should definitely be used with care. Furthermore, it has quite a few surprises, both good and bad (like the sequential read performance drop discussed earlier) for heavy consolidaters that warrant a closer look.
First of all, though we mentioned before that the Monitor remains the same across VMware’s virtualization products, not all of them can be put to use for the same purposes. VMware Server and Workstation, sturdy products though they may be, are not in any capacity meant to rival ESX in performance and scalability, and yet quite often perfectly viable testing setups are discarded due to their inferior performance. Hosted virtualization products are forced to comply with the existing OS’s scheduling mechanics, making them adequate enough to set up proof of concepts and development sandboxes, but not meant at all as a high-performance alternative to native situations.
Secondly, there are some very important choices to make when installing and running new VM’s. Though the “Guest OS” drop down list when setting up a new VM may seem like an unnecessary extra, it is actually responsible for the choice of monitor type and a plethora of optimizations and settings, including the choice of storage adapter, and the specific type of VMware Tools that will be installed. For that reason it’s important to choose the correct OS, or at least one that is as close as possible to the one that needs to be installed. A typical pitfall situation could be to select Windows 2000 as the guest operating system, but installing Windows 2003. This would force Windows 2003 to run with Binary Translation and Shadow Page Tables, even though hardware-assisted virtualization is available.
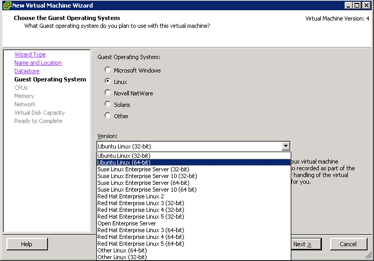
Preventing interrupts
Thirdly, as it turns out, not all OS’s are equally fit to be virtualized. As an OS operates through the use of timed interrupts to maintain control of a system, knowing how sensitive ESX is to interrupts, we need to make sure we are not using an OS that pushes this over the top. A standard Windows installation will send about 100 interrupts per second to every vCPU assigned to it, but some Linux 2.6 distributions (for example RHEL 5) have been known to send over 1000 per second, per vCPU. This generates quite some extra load for ESX, which has to keep up with the VM's demands through the use of a software-based timer rather than a hardware-based one. Luckily, this issue has been taken care of in later releases of Red Hat (5.1 onward), where a divider can be configured to reduce the amount of interrupts initiated.
For the same purpose, avoid adding any hardware devices to the VM that it doesn’t really need (be they USB or CDROM). All of these cause interrupts that could be done without, and even though their costs have reduced significantly, taking steps to prevent them go a long way.
Scheduling
A fun part of letting multiple systems make use of the same physical platform is thinking about the logistics required to make that happen, and to better grasp the way ESX makes its decisions scheduling wise, it might be interesting to dig a bit deeper into the underlying architecture. Though obviously it is built to be as robust as possible, there are still some ways to give it a hand.
Earlier in this article, we discussed NUMA, and how to make sure a VM is not making unnecessary node switches. The VMkernel’s scheduler is built to support NUMA as well as possible, but how does that work, and why are node switches impossible to prevent from time to time?
Up till ESX 3.5, it has been impossible to create a VM with over 4 vCPU’s in ESX. Why is that? Because VMware locks them into so-called cells, that force the vCPU’s to “live” together on a single socket. These cells are in reality no more than a construct, grouping physical CPU’s into a limited group which prevents scheduling outside the “cell”. In ESX 3.5, the standard cell size is 4 physical CPU’s, with one cell usually corresponding to one socket. This means that in dual core systems, a cell of size 4 would span 2 sockets.
The upside of a cell size of 4 on a quadcore NUMA system is that VM’s will never accidentally get scheduled on a “remote” socket. Because one cell is bound to one socket, and the VM can never leave its assigned cell, this prevents the potential overhead involved with socket migrations.
The downside of cell sizing is that they can really limit the scheduling options provided to ESX when the amount of physical cores available is no longer a power of 2, or the cell sizes get too cramped to allow for the scheduling of several VM’s in a single timeslot.
With standard settings, a dual socket 6-core Intel Dunnington or AMD Istanbul system would be divided up into 3 possible cell configurations. One cell bound to each socket, and one cell spanning the two sockets. This puts the VM’s stationed into the latter at a disadvantage, due to the required inter-vCPU communications slowing down, which would make scheduling “unfair”.
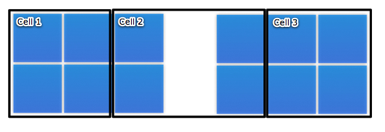
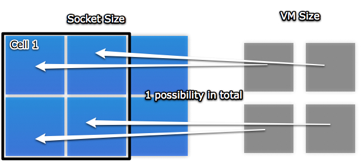
Luckily, it is possible to change the standard cell size to better suit these hexcores, by going into Advanced Settings on a VI client, selecting VMkernel and setting VMkernel.Boot.cpuCellSize to 6. The change should be implemented as soon as the ESX host is rebooted, and allowing 4-way VM’s to be scheduled a lot more freely on a single socket, without allowing it to migrate.
Changing the cell size to better reflect the amount of cores for Istanbul boosted performance in our vApus Mark I test by up to 25%. This performance improvement is easily explained by the large amount of scheduling possibilities added for the scheduler: When trying to fit a 4-way VM into a cell comprised of 4 physical cores, there is only ever one scheduling choice. When trying to fit that same VM into a cell comprised of 6 physical cores, there are suddenly 15 different ways to schedule the VM inside that cell, allowing the scheduler to choose the most optimal configuration in any given situation.
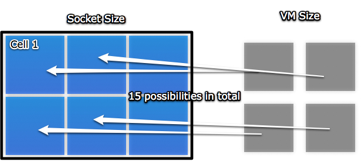
People who have made the switch to vSphere may have noticed there is no longer a possibility to change the cell size, as VMware has decided to tweak the way the scheduler operates. It will now configure itself automatically to best handle the socket size.
"Magic" memory
If you are already running ESX, you may be aware of the fact that it is still to this day the only hypervisor-based solution that allows for memory overcommitment. To get this to work, VMware has implemented three ways of reclaiming memory from a running VM: Page sharing, ballooning and swapping. To allow ESX to get the best out of these implementations, a final consideration when virtualizing would be to put VM’s with similar workloads and operating systems together on the same physical machine. Now, when running only a small amount of VM’s next to each other, this might not be a viable option, or seem to improve the situation much, but in heavy-duty environments, grouping similar VM’s together allows the hypervisor to free up a large amount of memory by sharing identical pages across the different systems. ESX scans through all pages at runtime to group the static parts of memory that each VM shares, allowing for example 5 idling Windows systems to take up little more RAM than a single one. This effect is made clear in the image below, in which VMware demonstrated the amount of memory saved across 4 VM’s, thanks to aggressive “page-sharing”, as VMware calls its technology.
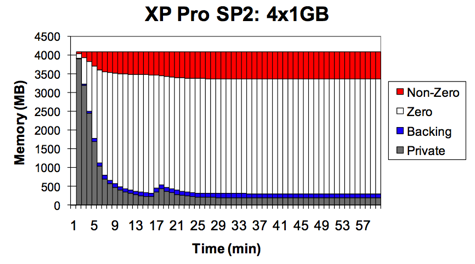
Page-sharing is just one of 3 technologies ESX uses to reclaim memory from its VM’s, the other two being ballooning and swapping. You can check the effect page-sharing has on your VM’s in esxtop’s memory screen.

The SHRD counter denotes the amount of memory in the VM that is shared with other VM’s, this includes zero’d out pages.
The ZERO counter denotes the amount of memory that has been zero’d out. These pages also count as shared ones, as every single “zero’d” page refers to the same zero’d physical segment.
SHRDSVD is the estimated amount of memory that is saved for that VM thanks to the page-sharing mechanism.
Also interesting are the MCTL-columns, that deal with the VM’s ballooning driver. MCTLSZ is the amount of memory that has been reclaimed through the use of the balloon-driver installed with VMware Tools. This “balloon” is actually no more than a process claiming the free memory on a VM, to artificially increase pressure on the VM’s OS. This way, the OS is forced to run as memory-efficiently as possible, allowing for as much memory as possible to be reclaimed for other VM’s, should the need arise.
Conclusion
Optimizing a workload for use with virtualization is no easy task, and quite often requires an IT admin to dive deep into the workings of their applications, as these can significantly impact their performance under ESX. On one side, it makes the job of today’s IT admins a lot more interesting than those of 10 years ago, on the other hand, it is all the more important to make a difference by keeping all that knowledge up to date. By implementing solid optimization practices, it is not just possible to squeeze those extra percent that make the difference out of a platform, but also to gain a strategic advantage in the harshness of today’s job climate.
The objective of this article was not to provide a tuning solution for every problem, but to share some of the pitfalls Anandtech IT and the Sizing Servers Lab have encountered in their experiences with VMware’s ESX, along with some solid advice provided by VMware themselves at VMworld Europe 2009.
This very moment, the team is working on similar in-depth research into Hyper-V and Xen, learning more as we move along and pit these solutions against each other, using our vApus Mark I workloads to test both the strengths and weaknesses of each platform. We hope you are looking forward to our hypervisor comparison; we definitely are.






