RAID Primer: What's in a number?
by Dave Robinet on September 7, 2007 12:00 PM EST- Posted in
- Storage
RAID 5
In an effort to strike a balance between performance and data redundancy, RAID 5 not only stripes data across multiple disks, but also writes a "parity" block among those disks which allows the array to recover from a single failed drive in the set. This parity block is staggered from one drive to the next, resulting in each drive having either a portion of the data that is trying to be read, or the parity block which allows the data to be reconstructed. In this way, the array gains some performance benefits in having the data striped among multiple disks, while being able to stay online after the failure of a single disk in the array.
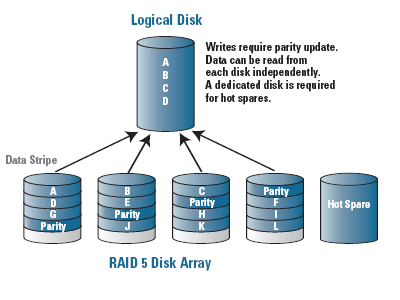
Rather than having a dedicated drive for parity as in the less-popular RAID levels 3 and 4, the parity sharing of RAID 5 allows for a more distributed drive access pattern, resulting in improved write performance and a more even disk wear pattern than with a dedicated parity drive.
In its optimal form, RAID 5 provides substantially faster read performance than a single drive or RAID 1 configuration, but write performance suffers due to the need to write (and sometimes recalculate) the parity information for the majority of writes performed. While this write performance is still faster than a single disk configuration in most cases, the true performance benefit of a RAID 5 array is in its read ability.
It should be noted that the read performance of a RAID 5 array improves as the number of disks in the array increases. This increase in disks, however, increases the odds of a disk failure in the array due to the law of averages, which results in a performance degradation during rebuilding operations. It also increases the likelihood of the entire array being unrecoverable if a second disk in the array fails before the first failed disk is replaced. In the image shown, the array contains a "hot spare" disk - in the event of a disk failure, this "hot spare" disk would be brought into the array to replace the failed disk immediately.
RAID 5 finds a comfortable home in most "read often, write infrequently" server applications which require long periods of uptime, such as web servers, file/print servers, and database servers. Dedicated RAID 5 controllers that include large amounts of RAM can negate much of the write performance penalty, but such setups are quite a bit more costly. Note also that simplified RAID 5 controllers exist that require the CPU to perform the parity calculations, which can result in write performance that is lower than a single drive.
Pros:
RAID 6 attempts to address the most glaring of the RAID 5 issues: The comparatively large window in which the array is in a dangerous state due to a failed disk.
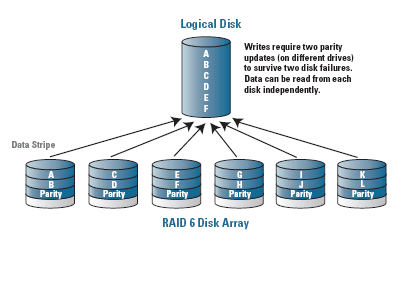
As in RAID 5, RAID 6 staggers its parity information across multiple drives. Its major difference, however, is that it writes two parity blocks for every stripe of data, which means that the array is capable of remaining accessible to the users even after having sustained two simultaneous drive failures. The advantage of a RAID 6 array versus a RAID 5 array with a hot spare risk is that no rebuilding is necessary to bring the last disk into the array in the event of a failure. In this sense, performance is more or less guaranteed after a single disk failure under RAID 6, whereas a significant performance hit occurs during the rebuilding required under RAID 5.
RAID 6's parity scheme is not simply multiple copies of the same parity information, but rather two different means of calculating parity information for the same data. This results in a much higher computing overhead than the already-intensive RAID 5 scheme, and a resulting increase in controller/CPU usage. This requirement for the second parity calculation and write, however, further adversely impacts the write performance of a RAID 6 array versus a RAID 5 solution.
RAID 6 is an excellent choice for both extremely mission-critical applications and in instances where large numbers of disks are intended to be used in the array to improve read performance. Because of this (and the poor write performance without special hardware), RAID 6 support is typically only included in high-end, expensive controller cards.
Pros:
In an effort to strike a balance between performance and data redundancy, RAID 5 not only stripes data across multiple disks, but also writes a "parity" block among those disks which allows the array to recover from a single failed drive in the set. This parity block is staggered from one drive to the next, resulting in each drive having either a portion of the data that is trying to be read, or the parity block which allows the data to be reconstructed. In this way, the array gains some performance benefits in having the data striped among multiple disks, while being able to stay online after the failure of a single disk in the array.
Rather than having a dedicated drive for parity as in the less-popular RAID levels 3 and 4, the parity sharing of RAID 5 allows for a more distributed drive access pattern, resulting in improved write performance and a more even disk wear pattern than with a dedicated parity drive.
In its optimal form, RAID 5 provides substantially faster read performance than a single drive or RAID 1 configuration, but write performance suffers due to the need to write (and sometimes recalculate) the parity information for the majority of writes performed. While this write performance is still faster than a single disk configuration in most cases, the true performance benefit of a RAID 5 array is in its read ability.
It should be noted that the read performance of a RAID 5 array improves as the number of disks in the array increases. This increase in disks, however, increases the odds of a disk failure in the array due to the law of averages, which results in a performance degradation during rebuilding operations. It also increases the likelihood of the entire array being unrecoverable if a second disk in the array fails before the first failed disk is replaced. In the image shown, the array contains a "hot spare" disk - in the event of a disk failure, this "hot spare" disk would be brought into the array to replace the failed disk immediately.
RAID 5 finds a comfortable home in most "read often, write infrequently" server applications which require long periods of uptime, such as web servers, file/print servers, and database servers. Dedicated RAID 5 controllers that include large amounts of RAM can negate much of the write performance penalty, but such setups are quite a bit more costly. Note also that simplified RAID 5 controllers exist that require the CPU to perform the parity calculations, which can result in write performance that is lower than a single drive.
Pros:
- Good usable amount of data (capacity is the sum of all but one drive in the set)
- Fault-tolerant - can survive one disk failure without impact to users
- Strong read performance
- Write performance (without a large controller cache) is substantially below that of RAID 0
- Expensive (either in terms of controller cost or CPU usage) due to parity calculations
RAID 6 attempts to address the most glaring of the RAID 5 issues: The comparatively large window in which the array is in a dangerous state due to a failed disk.
As in RAID 5, RAID 6 staggers its parity information across multiple drives. Its major difference, however, is that it writes two parity blocks for every stripe of data, which means that the array is capable of remaining accessible to the users even after having sustained two simultaneous drive failures. The advantage of a RAID 6 array versus a RAID 5 array with a hot spare risk is that no rebuilding is necessary to bring the last disk into the array in the event of a failure. In this sense, performance is more or less guaranteed after a single disk failure under RAID 6, whereas a significant performance hit occurs during the rebuilding required under RAID 5.
RAID 6's parity scheme is not simply multiple copies of the same parity information, but rather two different means of calculating parity information for the same data. This results in a much higher computing overhead than the already-intensive RAID 5 scheme, and a resulting increase in controller/CPU usage. This requirement for the second parity calculation and write, however, further adversely impacts the write performance of a RAID 6 array versus a RAID 5 solution.
RAID 6 is an excellent choice for both extremely mission-critical applications and in instances where large numbers of disks are intended to be used in the array to improve read performance. Because of this (and the poor write performance without special hardware), RAID 6 support is typically only included in high-end, expensive controller cards.
Pros:
- Fair usable amount of data (sum of all but two drives in the set)
- Provides more comfortable levels of redundancy for very large array sizes (8+ disks)
- Strong read performance
- Expensive (both in computing power, controller, and in additional "wasted" disks)
- Write performance is generally very poor compared to other RAID solutions








41 Comments
View All Comments
munim - Friday, September 7, 2007 - link
I don't understand what the parity portion is in RAID 5, anyone care to explain?drebo - Friday, September 7, 2007 - link
Simply: It's a peice of data that the RAID controller can use to calculate the value of either of the other pieces of data in the chunk in the event of a disk failure.Example: You have a three disk RAID 5 array. A file gets written in two pieces. Piece A gets written to disk one. Piece B gets written to disk two. The parity between the two is then generated and written to disk three. If disk one dies, the RAID controller can use Piece B and the parity data to generate what would have been Piece A. If disk two dies, the controller can generate Piece B. If disk three dies, the controller still has the original pieces of data. Thus, any single disk can fail before any data loss can occur.
RAID 5 is what is known as a distributed parity system, so the disk that holds parity alternated with each write. If a second file is written in the above example, disk one would get Piece A, disk two would get the parity, and disk three would get Piece B. This ensures that regardless of which disk dies, you always have two of the three pieces of data, which is all you need to get the original.
Zan Lynx - Tuesday, September 11, 2007 - link
The reason RAID-5 uses distributed parity is to balance the disk accesses.Most RAID-5 controllers do not read the parity data except during verification operations or when the array is degraded.
By rotating the parity blocks between disks 1-3, read operations can use all three disks instead of having a parity-only disk which is ignored by all reads.
ChronoReverse - Friday, September 7, 2007 - link
I understand how the fault tolerance in the best case is half the drives in the 1+0 scenario, but that's still not worse than the RAID 5 scenario where you can't lose more than 1 drive no matter what.So why was RAID 5 given a "Good" description while RAID 10/01 given a "Minimal" description?
drebo - Friday, September 7, 2007 - link
RAID 0+1 (also known as a mirror of stripes) turns into a straight RAID 0 after one disk dies. The only way it will support a two disk failure is if disks on the same leg of the mirror die. If one on each side dies, you lose everything. After one disk failure, you lose all remaining fault tolerance. RAID 10 (or a stripe of mirrors) will sustain two disk failures if the disks are on different legs of the array. If it loses both disks on a single leg, you lose everything. Thus, it is far more likely that you'll lose the wrong two disks.In a RAID 5 array, any single disk can be lost and you'll not lose anything--its position is irrelevant. Not only that, but a RAID 5 has better disk-to-storage efficiency (nx-1) when compared to RAID 0+1 and RAID 10 (nx/2). It's also less expensive to implement.
Overall, RAID 5 is one of the best fault tolerant features you can put into a system. RAID 6 is better, but it is also much more expensive.
ChronoReverse - Saturday, September 8, 2007 - link
So in RAID 5 you can lose any ONE drive.In RAID 1+0/0+1, you can also lose any ONE drive.
In RAID 5 you CANNOT lose a second drive.
In RAID 1+0/0+1, there's a CHANCE you might survive a second drive failure.
Therefore, RAID 5 is more fault-tolerant.
Brovane - Saturday, September 8, 2007 - link
Yes apparently to some people. Also one of the big bonus to Raid 0+1 is that you lose a drive and you do not suffer any performance degradation unlike RAID5 which until the RAID is rebuilt after a drive failure you take a big performance hit. If you are running a Exchange Cluster you cannot afford to take this performance hit during the middle of a busy work day unless you really do not like your helpdesk people. I think the one argument you could make is that a RAID 0+1 has more drives in a array to offer the same amount of storage as a RAID 5 volume so maybe you could make the statistical argument that the RAID 0+1 could be less fault tolerant. However to me this seems very tenuous.Dave Robinet - Saturday, September 8, 2007 - link
Good comments, and thanks for reading.You are, however, taking things a little out of context. Take a 6 drive configuration, for example. If you do a RAID 5 with four drives and two hotspares, you'll end up with the same usable capacity as a 6 disk RAID 0+1 - but with the "ability" to lose 3 drives.
Your comment about rebuilding is, however, completely backwards. You spend FAR more time rebuilding the mirrored set of a RAID 0+1 after a failed disk, because you need to rebuild the entire mirrored portion of array once again (since data has presumably changed, there's no parity, etc). (Don't believe me? Try it. ;)
Your general observation about being able to lose one disk in one or the other configuration is correct. You do need to compare apples-to-apples - a RAID 5 will offer you far more capacity if you build the same number of drives as in a 0+1, and a 0+1 will give you more performance. Apples-to-apples, though, you're going to get better redundancy OPTIONS out of the additional RAID 5 flexibility than you will with a 0+1.
Again, though, good points, and thanks again for reading.
dave
ChronoReverse - Sunday, September 9, 2007 - link
What do you mean by hotspares? Do you mean a drive that you can swap in immediately after a drive fails? If that's the case, while in terms of economics it might be three "spares" in terms of actual data redundancy, it's still just one drive. If a drive fails while the spare is filling, you've still lost data.In any case, it's quite clear that RAID will certainly give you more capacity, but the question was about the comment about data redundancy. I'll have to specify that it means to me how safe my data is in terms of absolute drive failures.
Brovane - Monday, September 10, 2007 - link
If you are using a SAN (Storage Area Network) were you might have say over 100+ disks were you build storage groups to assign to your servers that are connected into the SAN. This SAN will usually have various combinations of RAID 0,1,1_0,5. In this SAN you might have various types of disks says 300GB 10K FC and 146GB 15K FC Disks. You will keep a couple of these disks as hot spare. If say at 2AM the SAN detects in one of your RAID 1_0 Storage Groups that a disk has failed it will grab one of the hot spare disks and start re-building the RAID. The SAN will usually also send a alert of the various support teams that this has happened so the bad disk can be replaced. The SAN doesn't care where the hot spare is plugged into the SAN.The biggest issue that I see as a ding against RAID 5 vs RAID 0+1 is the performance hit when a drive fails in a RAID 5. With a RAID 0+1 you suffer no performance hit when a drive fails because there is no parity rebuilding. With RAID 5 you can take a good performance hit until the RAID is rebuilt because of the parity calculation. Also with a SAN setup you can mirror a RAID 0+1 between physical DAE so the storage group will still stay up in the unlikely event of a complete DAE failure. Also even though in a RAID 0+1 you will have to rebuild the complete disk in the event of a drive failure with 15K RPM and 4GB FC backbone on the SAN this happens faster than you would think even when dealing with 500GB volumes. if you very concerned about losing another disk before the rebuild is complete you could use SnapView on your SAN to take a SnapShot of the disk and copy this data to your backup volume.